

Storytime
Or, “how I set out to spend 15EURs and wound up spending 10x that”. That’s excluding the extra parts/upgrades.
Continue reading Fujitsu Primergy TX140 S2: Buyer’s Guide and NAS buildOr, “how I set out to spend 15EURs and wound up spending 10x that”. That’s excluding the extra parts/upgrades.
Continue reading Fujitsu Primergy TX140 S2: Buyer’s Guide and NAS buildIn the previous part, I learned how to write data to LTO4 tape, got frustrated and splurged on an LTO5 drive to take advantage of LTFS. The drive came – and it works! It even came with a free HP H222 SAS adapter and 2 new LTO5 tapes.

Yup, screams “serious business”.
Sounds like basic stuff but before LTFS, the only way you wrote to tape was through proprietary software you had to pay a lot for or use Linux’s tar+dd.
In a Discord chat I had with Chris, I try to figure out how to use meTokens, and what are the value dynamics around a personal token. I find that to get the most out of this token, nothing beats having a solid reputation and personal brand. In other words – it is one of many possible funding systems.
(I actually use a different chat handle IRL)
[10:57 PM] chiwbaka: I just added collateral to the tune of 0.1 ETH to my token, but it says the Total Supply is 1000 - same as before. Is this supposed to happen?
[11:00 PM] CBobRobison | meTokens: Yes. If you add collateral, you're only increasing the amount of ETH backing the already existing meTokens. If you want to increase the supply, then you'll need to buy/mint new meTokens
[11:25 PM] chiwbaka: I thought my collateral was supposed to be my time/services? @CBobRobison | meTokens
When I was young, I downloaded a lot, and burned a lot of CDRs and DVD-Rs. Nothing would ever fit onto them, so I’d have to split movies up, or put some episodes of an anime series here and another there, and that disc had a few megabytes free, so there went a few more episodes… this was a major pain in the ass.
I have also since amassed a 600GB music+photos collection, which I’d hate to lose to silent data corruption, drive failure, ransomware, theft or whatever. No matter how many layers Bluray had, it just wasn’t enough – imagine figuring out how to split all this between 12 BD-R DLs.

The answer: a Quantum LTO4 drive (~200EUR). It’s much longer than a Bluray drive, much noisier, much hotter, and even requires an additional SAS HBA (so all in all, very exotic and sexy). Each tape is 800GB and costs 10-20EURs, and unlike DVD-Rs going bad, tape is much more reliable (all digital movie footage, especially digitized film, is stored on tape these days).
* 1. Introduction
* 2. Personal currencies – plausible?
* 3. Examples
* 3.1. Dance Teacher
* 3.2. Photographer
* 3.3. Software developer
* 3.4. Models
* 3.5. Doctors
* 3.6. Journalists/historians
* 3.7. Film directors
* 4. Final Thoughts

In this pilot installment of Chiwbaka’s Chainterviews, Chris Robison, the founder of meTokens, discusses a truly out-there concept – making your own personal currency. He also gives several examples of how dancers, teachers, musicians, film directors and artists of all kinds can benefit from this strange new invention.
Fittingly he now has his own token, $CBOB! Each CBOB is worth 0.0038EUR as of the time of publication. I wonder what this means…
Think of your friends and how you have tit for tat with one another. There is an unspoken agreement to keep track of such favours implicitly, and if you have a friend who really keeps track of every cent he spent when doing favours for another, you’d all think he was a miser and keep your distance in some fashion.
Meanwhile, to exchange favours with the rest of the world, you use an abstraction of value called money. Over there, business is strictly business.
Now imagine if the tit for tat network could be expanded to not just include your close friends, but people who know about and presumably like you. Like your fans, or merely acquaintances who think you’re cool because they don’t yet know you eat boogers in the bathroom. Tit for tats could also be exchanged through a mutual acquaintance, enabling the exchange of favours with a total stranger.
Of course you’d need to keep track of all this explicitly, with currencies.
Could such a network reduce the importance of money in our lives/make transactions more personal, and abolish the desperate need to get rich at all costs?
Roll lets you create ERC20 personal tokens.
MeTokens seems to be the same thing, but adds a bonding curve, making your tokens more expensive as demand for them increases.
Trustlines an IOU exchanging network just like Lightning (Bitcoin), but mostly for fiat currencies and the integrated “Beer” currency.
Circles UBI an IOU exchanging network, except that these are personal tokens, which are replenished daily (it is a UBI).
Although this won’t replace money altogether, this form of explicit tit for tat could become a way of socially signaling you are closer together. Great way for famous people to make you pay more to feel more included, artists to rally their highest paying patrons etc.
Hippies will love this, and it’ll become even easier for them to live without money now. They might even think of this as money and start a movement to abolish this…
Value perception remains as important as ever. For your personal tokens to have value, you must make people see the value in you. This is not easy. And you must back up your tokens when called upon.
On the first week of March, I got the coronavirus. This is my experience at accelerating my recovery from it. The government was of no help, as usual.

After going to Paris for EthCC, I got a cold. It was manageable at first, until the day I had to fly back to Berlin, because I thought hey, my flight is so early in the morning, might as well save money by sleeping over at the airport instead of a hostel!

Except that I didn’t even get to the airport in time to sleep, because I was having too much fun dancing zouk. In the end it was 4am, I couldn’t sleep on the bus because I was cold and afraid I might miss the stop at the airport, and when I had finally walked to the boarding gate, there wasn’t enough time to get proper sleep anyway.

There the cold really stopped being a sniffle and I had to blow my nose every now and then.
An aside about the Paris airport: incredibly, you will see homeless people sleeping in the airport. I don’t blame them, but when they piss on a wall indoors, when they could have just walked to a restroom, they really should be kicked out. I have no idea who said Paris was the city of romance.
Once I returned to Berlin, I slept with a hot water bottle. My cold improved immediately, and my mucus became green. So much for the cold.
But a day later, while walking back home, I felt the beginnings of a fever.
A few days ago I discovered cadCAD while researching token engineering, and in a fit of sudden creativity, I coded up two simulations to life’s questions that had been subtly bothering me.
I know I’ll get a lot of flak from people about the dating simulator, even from dating coaches I took advice from, where making a simulation is “thinking too much” to them. But being able to put hard numbers on my expectations is the biggest thing I never knew I was missing.
It’s a framework to make testing simulations of complex systems easier.
Or more specifically: you write your actors and strategies and environmental conditions. cadCAD turns this into a pandas.DataFrame and runs the simulation a number of times for you, letting you switch easily between simulation strategies.
Lifesim 2 – a job search situation simulator
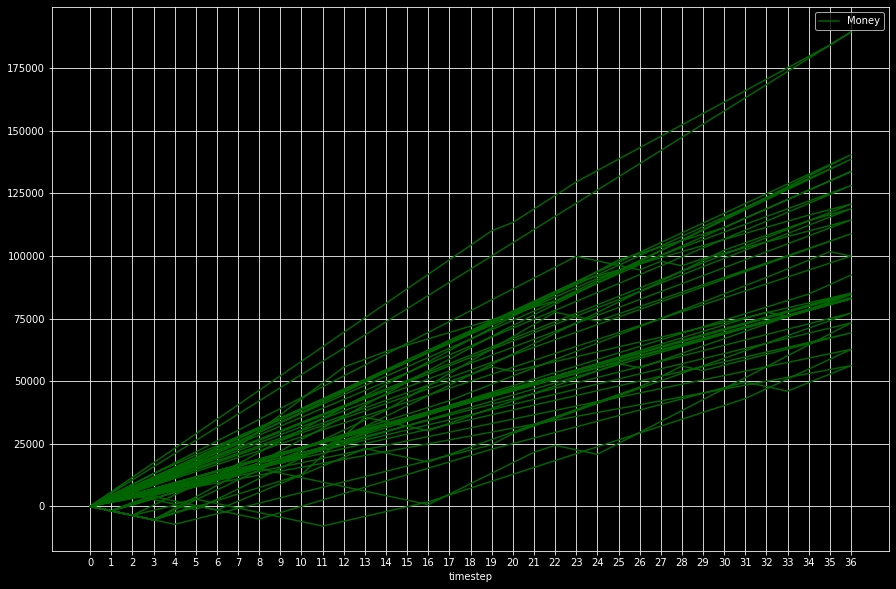
Your bank account balance over 3 years, assuming you keep living expenses at 1800EUR and you look for 3 jobs per month between jobs
Suppose the following:
* You’re looking for a job.
* Your monthly expenses are 1800EUR.
* You have a 20% chance of getting a job once you’ve applied for it (IRL this means personal contact, not sending your resume somewhere)
* Most jobs pay around 3000EUR +- 2000EUR.
* Each month, a job has a 10% chance of firing you.
* You can afford to make 2-3 personal connections per month that lead to jobs.
* Your minimum criteria: job must pay at least your monthly living expenses.
What will your bank account look like in 3 years?
To play with the numbers, set up Jupyter notebook and the Python virtual environment with requirements.txt.
To guarantee that your balance will be positive in 3 years, you must look for jobs which pay 2 * monthly living expenses, and you must meet 2-3 people who can provide such jobs per month.
Suppose you’re a 5. How many girls should you ask out per day, and how choosy can you be, to have a satisfactory dating life?
Girlsim – how choosy can you afford to be?
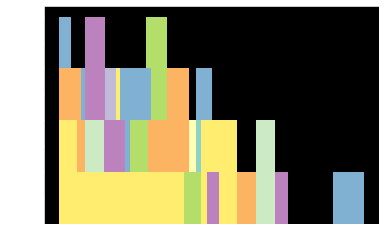
If you’re an ‘8’ who only dates ‘7s and up’, here’s your dating history over 30 lifetimes, assuming you’ve asked out 1000 girls (each colour is a different lifetime)
Personally, “the feeling of sexual abundance” is important, i.e. you’re not desperate to cling on to her because she’s the only girl who’ll like you back in a long long time.
There are 2 ways of defining this. Pick one.
1000 girls is 1 year of asking out 3 girls a day. At least 1 girl a month is a reasonable expectation.
The hotness distribution of girls who accepted you must look like a normal distribution, not discrete.
There’s a big gulf between knowing and doing.
I spent a lot of time thinking of how to think so that I could generate moves. That helped to a certain extent, but I just kept thinking fruitlessly instead of just going out there and making mistakes.
Mistakes are great improvisation opportunities – and they make it more fun to dance with beginners (as long as they follow the basics). You can always alter the tension in the embrace/grip, and this changes the character of the dance and makes new things possible.
It’s not good enough to be good.
You need to be socially connected.
Going to a milonga, salsa party or any kind of partner dance social? The good dancers are usually too busy talking and dancing with other people for you to muscle into the situation in a smooth way.
Same with dating and (probably) making money too. Cold approach is not something you should use all the time, but an additional skill in your pocket that you pull out when the time is right (or if you have no other choice).
What do women want? Probably not what you think they want.
It’s easy to think that women want to see your fancy moves, your cars, your riches. No doubt this catches attention – but catching someone’s attention is just getting your foot in the door.
Many women also mistake attention for attraction, the classic example? Women who wear stockings in winter. Have they got our attention? Yes. Are we attracted? Maybe… but she’s obviously got issues. Similarly, if a leader looks great when dancing, but actually isn’t fun to dance with, or leads moves roughly for the follower, she won’t speak well of him afterwards.
Think of your fancy moves, clothing, watches, cars as the candy wrapper. In the end, the chocolate still needs to taste at least as good as the others, if not better.
What’s the chocolate in dance? It’s the feeling of understanding someone at a level where no words are needed. See Cory Henry and Yoran Vroom at 3:53. Telepathic understanding. Emotional sync.
Maybe that’s why women use so many words and emojis with each other, and obsess over how every part of their behaviour comes across. It’s all about establishing emotional harmony (this implies fitting in).
Appearance and reality, just like attention and attraction, are quite disconnected.
Germany is a strange country – a restaurant’s decor correlates directly with its food quality, whereas in Asia, you purposely go to shabby looking stalls by the side of the road to get great chicken rice that’s just as good as fancy restaurants.
For Germans, eating out is a social occasion, and the food is just one part of it. The atmosphere of course contributes to the occasion, and any restaurateur who neglects that is probably similarly sloppy in other aspects.
This is a classic correlation != causation example that only happened because of a particular mindset towards eating.
Apparently, I appear confident and know what I’m doing.
Or rather, women get insecure about their own abilities too and you have to constantly reassure them that yes, I did intend to lead that move.
I heard some women are like that with their looks.
Again, appearance and reality are two very different things. Sometimes they are connected. Beware this mental shortcut.
As you decide for a particular style, you will alienate people.
Dress normal and everybody will think nothing of you.
Dress preppy and some people will think you’re posing.
Dress goth and most people will think you’re “weird”.
Dress outdoorsy and you won’t stand out to the preppy people.
There was a time when I never consciously thought about what I was doing. I made no progress and that wasn’t good.
Then I started thinking. I saw results, I made progress and that was good.
So I started thinking even more, because I wanted to succeed faster. I built thought frameworks (general rules to guide my thinking) as I learned about new fields. It took me a long time to realize that my rate of progress hadn’t changed at all, and I was burning more energy for nothing.
There were others who hadn’t built a clear framework of how to think. But it didn’t matter. Because of their social position, because they took action, they got the hot girl or were rich. Thinking the right way can lead you to success, but is only one component.
“A change in perspective is worth 80 IQ points” – Alan Kay
What’s the easiest way to get another perspective? Ask someone else. Sure, it is possible to imagine another perspective, but asking is just easier, plus you get to strengthen a social connection.
Sometimes, you don’t know what you don’t know – and this can overturn your thought framework overnight. Exploration is the answer here, and this can be time consuming.
Lastly, after having built many thought frameworks, I noticed most of them resulted in sound common sense. I didn’t have to spend so much energy building them in the first place!
Caveat: some bad life advice masquerades as common sense. It can really help to think through “common sense” advice to see if it really is “common sense” or some misguided line that an unfortunate, misinformed, unfortunately loud individual is spewing on social media.
Thinking is simply bringing your subconscious thoughts up into the consciousness, where we can think about it faster using reason instead of emotion, overcome biases installed by society, overcome bad habits and misleading values in our subconscious, gain a clear vision of where we want to go etc. Words are the handles by which we grab and manipulate our thoughts from the sea of our subconscious. Word choice is very, very important.
But the consciousness is simply a tool, and one shouldn’t depend on one tool exclusively.
I go through life in a daze, not noticing the beauty in my surroundings, forgetting upcoming chores/appointments which are important but not urgent, and as a result I have to construct routines to get my life back on track, which makes me rigid and (ugh) German.
To improve one’s skills, there is no limit to the conscious complexity one can construct. But actually the most fun way is to improvise, boosting efficiency with honest communication and a very short iteration cycle.
When learning a new topic, a framework to guide your thoughts, a chosen set of values to strive towards from the very beginning, will help you achieve your goal quickly. (source: dancing experience)
When you have a gut feeling, but you just can’t put it into words. Not bringing it up to your subconscious could waste months, years of your time. Open a blank document and just start typing whatever comes to your mind, dumping your stream of consciousness into words (very effective, source: The Ultimate Commonplace System).
When building new processes to streamline your life. Within moderation: do not make a whole new routine and force yourself to commit to that. Instead, see what trhythm you naturally fall into and make slight tweaks to that. This is a good balance between enjoying life and improvement. Discipline is a finite resource after all.
I used to meditate to turn my brain off. Now I’ve rediscovered a better way from my childhood: video games, anime, tinkering with long lost hobbies. Wall Street Playboys would deride it as a waste of time, but one must waste a bit of anything once in a while.
The trick is to stop playing once you aren’t thinking about the original subject anymore, but your brain isn’t yet totally hooked on the game either. Video games can make your brain noisy and distracted too.
If you’re asking this question, you most certainly are. Remember a time when you weren’t under pressure to deliver, like your childhood. Then, in this quiet space that you’ve finally allowed yourself, listen to your gut.
You already know what to do.