I have an audiobook, but I wasn’t satisfied with the chapters. They were just numbers, and didn’t match with the chapters in the ebook.
This was the result.
First, use ffprobe to confirm the m4a file has chapters. We don’t want to figure out the timestamps ourselves.
ffprobe Morgan_Housel_-_The_Psychology_of_Money.m4a
ffprobe version n6.0 Copyright (c) 2007-2023 the FFmpeg developers
built with gcc 13.2.1 (GCC) 20230801
...
[mov,mp4,m4a,3gp,3g2,mj2 @ 0x55cd72a08740] stream 0, timescale not set
Input #0, mov,mp4,m4a,3gp,3g2,mj2, from 'Morgan_Housel_-_The_Psychology_of_Money.m4a':
Metadata:
major_brand : isom
minor_version : 512
compatible_brands: isomiso2mp41
title : The Psychology of Money: Timeless Lessons on Wealth, Greed, and Happiness
artist : Morgan Housel
composer : Chris Hill
album : The Psychology of Money: Timeless Lessons on Wealth, Greed, and Happiness
date : 2020
encoder : inAudible 1.97
comment : Money - investing, personal finance, and business decisions - is typically taught as a math-based field, where data and formulas tell us exactly what to do. But in the real world people don’t make financial decisions on a spreadsheet. They make them at
genre : Audiobook
description : Money - investing, personal finance, and business decisions - is typically taught as a math-based field, where data and formulas tell us exactly what to do. But in the real world people don’t make financial decisions on a spreadsheet. They make them at
Duration: 05:48:30.64, start: 0.000000, bitrate: 63 kb/s
Chapters:
Chapter #0:0: start 0.000000, end 13.606000
Metadata:
title : 001
Chapter #0:1: start 13.606000, end 804.571000
Metadata:
title : 002
Chapter #0:2: start 804.571000, end 1981.405000
Metadata:
title : 003
Chapter #0:3: start 1981.405000, end 3212.387000
Metadata:
title : 004
Chapter #0:4: start 3212.387000, end 4043.987000
Metadata:
...
Pretty good, it contains enough metadata that I can probably rename it straight into a m4b.
# Dump the chapters, which will be in .ttxt format
$ MP4Box -dump-chap book.m4b
# Add the improved chapters back to the m4b
# MP4Box will edit the original file by default. We want that, because otherwise we will have to explicitly copy over the cover image, the artist/genre/encoder/composer metadata...
$ MP4Box -chap book.ttxt Psychology\ of\ Money\ -\ Morgan\ Housel.m4b
Perfect. The finished audiobook is a joy to browse through.
Recently I tried to use GPT-4 to analyze dove-foundation/dove in preparation for a huge refactor. This is similar to feeding in PDFs and asking questions of it.
llama-index and langchain were famous in this space (loading documents and indexing), but some people said they were overly complex, so I spent some time on griptape, simpleaichat. https://www.youtube.com/watch?v=eQHhB1Z3fIA
But they seemed too simplistic. As I delved deeper into langchain, I didn’t find it was too complicated. Rather, it was very flexible and documentation was splendid.
When I asked GPT4 about the code, sometimes it would reply that not enough context was provided or that no code was provided. That’s weird, because I had gotten langchain to index the data. Time to dig deeper into what was really going on.
Code Splitting vs Text Splitting.
Turns out, when you feed text into langchain, it splits it up into chunks. And by default it splits them up by periods. Which makes sense for normal text, but not code. So you need a splitter that can understand code and split things up without mangling the meaning.
The model started to give useful output more often. Being able to see the chunks on Deeplake’s web UI helped a lot.
Must I use Deeplake?
As it turns out, the AI doesn’t have enough working memory (‘context’ is the technical word) to keep the whole codebase in mind. So people insert a database/index in between, which reads your data, determines what chunks of code are relevant to the question you’re asking and sends them together to the AI.
The tutorial told me to use Deeplake for the database/index, but I knew Deeplake was just a cloud play for something that doesn’t really need to be on the cloud (isn’t this familiar, fellow developers). Having a database/index isn’t something you need a cloud account for, you should be able to run that on your own computer.
Chroma is langchain’s built in database/index. It was terrible. I asked a question about evm.go and it didn’t even give the file to GPT4, only 2 results were relevant.
Then I tried an Ensemble retriever, BM25+FAISS. I asked the question “what does Observer.SaveAndPush()` do and paused my script to see what supporting code snippets the database/index would send to GPT4 to help make sense of my question.
pretty_print_docs(retriever.get_relevant_documents("what does Observer.SaveAndPush do?"))
Document 1 ({'source': '/home/shinichi/source/work/dove/bird/observer/observer.go'}):
func (d *Observer) SaveAndPush(event ev.EventObserved) {
// Directly provide Job status data to the executor service
// the "standard" way to do this would be to have the executor check in
// with a contract on DoveChain that pulls data from EventStorage.sol
// Specifically, the ExecutionQueue should use UELs to get Status data from
// EventStorage.sol? Future ToDo
if event.ChainName == "DoveGeth" &&
event.ContractAddress == d.config.ExecutionQueueAddress.String() {
d.modLog.Info("New ExecutionQueueEvent", "event", event)
abi, err := abi.JSON(strings.NewReader(execution_queue.ExecutionQueueABI))
if err != nil {
// This shall not happen
d.modLog.Info("OBS/EXC: ExecutionQueueAbi parse failed", "err", err)
return
}
----------------------------------------------------------------------------------------------------
Document 2 ({'source': '/home/shinichi/source/work/dove/bird/observer/observer.go'}):
package observer
import (
"bytes"
//"encoding/json"
"strings"
"time"
"github.com/dove-foundation/dove/bird/config"
"github.com/dove-foundation/dove/bird/contracts/execution_queue"
"github.com/dove-foundation/dove/bird/contracts/handle"
"github.com/dove-foundation/dove/bird/executor"
"github.com/dove-foundation/dove/bird/chain_service"
drivers "github.com/dove-foundation/dove/bird/drivers"
eventbrowserdb "github.com/dove-foundation/dove/bird/event_api"
pool "github.com/dove-foundation/dove/bird/eventpool"
ev "github.com/dove-foundation/dove/bird/events"
p2p "github.com/dove-foundation/dove/bird/p2p"
reshare_monitor "github.com/dove-foundation/dove/bird/reshare_monitor"
tbls "github.com/dove-foundation/dove/bird/tbls"
logger "github.com/dove-foundation/dove/bird/logger"
log "github.com/inconshreveable/log15"
----------------------------------------------------------------------------------------------------
Document 3 ({'source': '/home/shinichi/source/work/dove/bird/observer/observer.go'}):
func (d *Observer) reportMaliciousExecutor(executor common.Address, eventKey common.Hash) {
self := d.config.MyAddress == executor
if !self {
tx, err := d.chainService.ReportBird(executor, chain_service.JOB_RELAY_FAULTY, eventKey)
if err != nil {
d.modLog.Error("OBS/EXEC: Failed to report malicious executor", "error", err)
} else {
d.modLog.Info("OBS/EXEC: Report malicious executor success", "txHash", tx)
}
}
}
// Verify the transaction hash updated by executor by checking whether
// executor called the correct contract and passed the correct parameters
// based on dispatched information from ExecutionQueue.sol
func (d *Observer) verifyJobTX_Save_Push(
jobId [32]byte,
txHash string,
event ev.EventObserved) {
d.modLog.Info("OBS/EXEC: VerifyJobTransaction",
"JobId", common.BytesToHash(jobId[:]).Hex()[2:9])
abi, err := abi.JSON(strings.NewReader(handle.HandleABI))
if err != nil {
d.modLog.Error("OBS/EXEC: Failed to parse HandleABI", "error", err)
return
}
----------------------------------------------------------------------------------------------------
Document 4 ({'source': '/home/shinichi/source/work/dove/bird/observer/observer.go'}):
var Exit = make(chan bool)
type Observer struct {
chainConfigs []config.ChainConfig
config config.MasterConfig
watching *ev.Watching
eventPool *pool.EventPool
eventMiner *pool.EventMiner
transport p2p.P2P
modLog log.Logger
chainService chain_service.ChainService
executor *executor.Executor
executorAddress common.Address
chainHandlers map[int64]drivers.ChainHandler
eventChannel chan ev.EventObserved
errorChannel chan error
}
----------------------------------------------------------------------------------------------------
Document 5 ({'source': '/home/shinichi/source/work/dove/bird/observer/observer.go'}):
/*
This Observer takes information for _one_ chain, and then looks for events on that chain.
Note that this code is not well written - e.g. we don't filter eventsConfig
----------------------------------------------------------------------------------------------------
Document 6 ({'source': '/home/shinichi/source/work/dove/bird/event_api/event_api_interface.go'}):
package eventbrowserdb
import (
"github.com/dove-foundation/dove/bird/events"
"github.com/ethereum/go-ethereum/common"
)
type EventApiInterface interface {
SaveNewEvent(ev events.EventObserved,
coreHash common.Hash)
SaveSubmitterEventHash(eventKey string,
txHash string)
SaveSubmitterError(eventKey string,
errMsg string)
SaveAction(observerId common.Address,
eventKey string,
coreHash string,
timestamp uint64,
actionName string)
SaveActionWithData(observerId common.Address,
eventKey string,
coreHash string,
timestamp uint64,
actionName string,
actionData []byte)
}
----------------------------------------------------------------------------------------------------
Document 7 ({'source': '/home/shinichi/source/work/dove/bird/cmd/root.go'}):
go ob.Start()
<-observer.Exit // no message is ever sent to this channel, so it just serves as a block for the goroutines to run
return nil
},
}
----------------------------------------------------------------------------------------------------
Document 8 ({'source': '/home/shinichi/source/work/dove/bird/contracts/events_to_watch/events_to_watch.go'}):
nfirmations\",\"type\":\"uint64\"},{\"internalType\":\"uint64\",\"name\":\"ObservationStartBlock\",\"type\":\"uint64\"},{\"internalType\":\"bool\",\"name\":\"OverrideSender\",\"type\":\"bool\"}],\"internalType\":\"structEventsToWatch.Event\",\"name\":\"\",\"type\":\"tuple\"}],\"stateMutability\":\"view\",\"type\":\"function\"},{\"inputs\":[{\"internalType\":\"bytes32\",\"name\":\"_eventKey\",\"type\":\"bytes32\"}],\"name\":\"getEventKeyIndex\",\"outputs\":[{\"internalType\":\"int256\",\"name\":\"\",\"type\":\"int256\"}],\"stateMutability\":\"view\",\"type\":\"function\"},{\"inputs\":[{\"internalType\":\"bytes32\",\"name\":\"eventKey\",\"type\":\"bytes32\"}],\"name\":\"getFollowUpAction\",\"outputs\":[{\"components\":[{\"internalType\":\"string\",\"name\":\"MethodName\",\"type\":\"string\"},{\"internalType\":\"address\",\"name\":\"ContractAddress\",\"type\":\"address\"}],\"internalType\":\"structEventsToWatch.FollowUpAction\",\"name\":\"\",\"type\":\"tuple\"}],\"stateMutability\":\"view
----------------------------------------------------------------------------------------------------
Document 9 ({'source': '/home/shinichi/source/work/dove/bird/drivers/bitcoin.go'}):
*/
----------------------------------------------------------------------------------------------------
Document 10 ({'source': '/home/shinichi/source/work/dove/bird/drivers/bitcoin_test.go'}):
Even a novice programmer could see that only Documents 1, 3, 4 are relevant to the question at hand, but even then those weren’t the full function bodies, and the subfunctions that SaveAndPush() called weren’t even included, so how could GPT4 even give a satisfactory answer?
Integrating a language server that actually understands the programming language like gopls is really needed to understand what’s relevant to the question instead of a stupid search method.
Ah, Github Copilot
Then I remembered I had a Github Copilot subscription. It just makes sense that my IDE would understand enough about the code to send the relevant code to GPT.
I immediately installed Visual Studio Code and forgot about Code OSS. When it comes to cutting edge technology, open source software tends to disappoint. It’s just the way it is, unfortunately. For interoperability and commoditization, open source software is good.
Overall, AI cannot understand an entire codebase. This means it can’t help with design/architecture, but it can help with small annoying problems. With small enough code snippets, it can read and analyze code to find problems really quickly.
Supposedly Anthropic Claude-2 is better than GPT4 at coding and way cheaper (I spent about 3-4USD on this experiment) but for some reason it’s not available outside of the US.
I’ve said this before in many private events but I guess I should finally put this into writing.
The Body-State Analogy
Cells come together to form bodies, just like humans come together to form states. Blood flows between the cells, around passing value (nutrients, oxygen). If the body doesn’t appreciate a particular body part’s function, less blood flows to that part. And so it is with money too – the more valuable an industry is perceived, the more investments and resources go into it.
just told the AI to draw “abstract art that represents an analogy”. pretty good
Taking the Analogy Further
Organs -> Specialization: just like cells come together to form organs with specific functions in the body, people or companies specialize in certain industries. Immune System -> Regulations: regulations can be seen as the immune system of a country, keeping foreign cells from entering the body or causing harm. We all say it stifles innovation – that’s right, regulations protect the status quo. Circulatory System -> Infrastructure: transportation networks and financial institutions are like blood vessels. Communication infrastructure would then be the nervous system. Homeostasis -> Economic Balance: Homeostasis is the maintenance of stable internal conditions (medical). Similarly, a state also needs to maintain economic balance by managing inflation, unemployment and fiscal policies.
Crypto is a blood looking for a body
In 2019, I had a choice to make. Go into AI, or crypto? I chose crypto – because it had the potential to be more disruptive – it could potentially upheave entire countries and change the way we transact.
ooh this AI stuff is fun. I guess I’ll put more photos in now like you’re supposed to in blogposts
Fast forward to today, and bodies have successfully (as in, the country continues to exist and hasn’t been totally disrupted) managed their relationship with crypto by either regulating it away or embracing it wholeheartedly – strategies differ.
DAOs (analogous to companies) exist based on coins, but still rely on traditional infrastructure provided by nation-states to exist. There is no state-level entity that uses crypto as its blood.
Could Balaji Srinivasan’s Network State be such an entity?
Bitcoin has created a public utility (payment rails/value storage) out of thin air just by taking advantage of people’s greed. To see how far we can replicate Bitcoin’s success in other real life businesses, let’s try to decentralize several businesses.
Manufacturing a Table
The steps in making a table are: make a design, source material, work the material into shapes, assemble pieces.
Design: extremely subjective. Many people will come up with different designs, and any decision has to be made by a human with ‘good taste’.
Material sourcing: the choice of a material over another depends not just on its performance, suitability to the design, but also its price and availability. Which means a human will make this decision.
Working the material: perhaps a machine can shape the material and inspect the finished product. Realistically though a human is involved.
Assembling parts: a machine could do this, but humans are still needed for QC.
Conclusion: table manufacturing has no business being ‘decentralized’ a la Bitcoin, because the work done is physical and human taste is needed to judge almost all parts of it.
Plus, being ‘decentralized’ wouldn’t bring any benefits for the end user.
Email Hosting
End user benefit: an email service that doesn’t read its users’ email, but yet doesn’t need a user to pay money.
Steps: Setup hardware, software, hosting service: same as when setting up your own blockchain node
Hey, this already exists and is called self-hosting! But self-hosting is just running the email server for yourself, let’s go further than that and offer the service to others.
To prevent abuse we have to ask for a cost again, which could either be
time (run the email server on your own machine)
token (fiat money or cryptocurrency), which begs the question: how should the user earn the token. Perhaps he could host the software too, but then that would be back to self-hosting.
Conclusion: email is already decentralized, and we are simply being spoilt by Gmail being free. Everything has a cost.
Scraping webpages: This seems like a great task to hand off to random distributed computers, except it isn’t: the content of a URL should be objective, but isn’t – pages change with time, and even by IP geolocation. Thus the truth is subjective. We must guard against an attacker who wants to game the recommendation algorithm by submitting a fake version of his webpage. We can do this economically by requiring that tokens be staked, but it should not be the only safeguard as it depends on the token’s price.
Alright, scraping webpages takes resources and introduces subjectivity. Let’s instead record which users liked which items, which means we don’t need to know anything about the URL except that it isn’t a 404.
A like/dislike button in the web browser influences what is shown in the browser sidebar, called ‘Similar Pages’.
The user earns tokens by expressing his like/dislike for pages. To make this data available on a distributed database, he stakes tokens on his preferences, and receives the tokens as his reward for adding his preferences to the dataset.
However, what a user likes/dislikes is subjective, and any participant trying to game the system (to earn tokens, to establish false relationships between content) can hide behind that argument and the system cannot slash him for acting dishonestly. Again we find that the difficulty of verifying something external in an automated way is the problem.
OK let’s go back to scraping webpages and labeling them using an AI. It’s less subjective and therefore less complex. Companies have done this before. Maybe we can keep the centralized company but reimagine the economics.
As it turns out, there are search engines like Neeva and Kagi. Both are paid and seem to deliver less SEO clickbaity results. Perhaps we’re all just spoiled and have to pay after all.
It turns out you do need humans in the loop to make good search results after all, so at some point you will have to pay humans. According to Wikimedia Foundation Financials humans are the biggest expense item, so even if you decentralize the system enough so that it runs entirely on users’ computers, you have to pay humans to maintain it.
Humans currently maintain Bitcoin, Ethereum and Solana, so this isn’t a showstopper. So why is humanity willing to pay for decentralized computation when it’s not willing to pay for search, which builds upon computation and storage?
Because search is already available elsewhere for free, and it’s good enough, whereas immutable, censorship-resistant computation always costs, no matter where you look. Google is bad, but I can work around it, and there are other free search engines.
So just because something is immensely valuable (like water) people aren’t going to pay for it. People will only pay when their relative circumstances force them to.
Learnings
Decentralization adds massive complexity because of the need for objective, easily verifiable truth.
Bitcoin is simple because it relies on simple objective truth (mathematics) which does not rely on external data. This allows it to know for sure when someone deserves its newly minted currency.
Aligned values and being decentralized are two different things. Search engines like Neeva and Kagi show that if users pay, values are aligned.
To align values between a user and a provider, a cost must be paid, either in a token, or time (participating in running the system). If there is a token, the question is how does the user earn it, besides buying it with fiat money.
If humans are doing work in the system, they will be the bulk of the costs. Thus you will eventually need to pay money for the token (otherwise it will go down in value), or just pay money for the service like in real life.
People don’t pay for absolute value. They pay when they can’t get that value anywhere else (or not without a steep cost in time/energy).
First there was the currency (Bitcoin). Then came decentralized organizations (DAOs, think companies). Now here comes an even larger scale organization – the decentralized state.
Since there are no countries in this new world, or if they do, they’re only partially relevant (like churches today), I won’t need a passport to travel to large areas of land. Instead, I will need a NFT in my Ethereum wallet to get into this building, or that event.
The network state which I belong to cannot provide me with clean water, fresh air, a sewage system, since it doesn’t control a large contiguous swath of land, only individual pockets of land that its members somehow ‘own’ (let’s not debate how that ownership is established/enforced just yet). Instead, it has partnerships with CleanAirDAO, CleanWaterDAO, which are global in scope and also service other network states. What’s this called again, horizontal disaggregation?
Roads need to be built and maintained. The RoadBuidlersDAO exists in this contiguous swath of land, but there are competing road building DAOs as well, perhaps specializing in other territories. Most companies today are entities confined within their country by geography and by incorporation. In this new world though, these DAOs or companies operate much the same as before, except that they’re incorporated globally by default (since they’re just on the blockchain).
A smartphone/computer manufacturer rises up to rival Apple (let’s call it Zucchini). Its specialty is that its products are open and easily serviceable (we know, no one cares). It has operations all over the world, especially in (former?) China with some DAOs there, software development spread all over the world, and a tight knit, very local marketing/design team somewhere. Yes, it’s not very different from today’s Apple. Zucchini owns many locations (perhaps it is a network state by itself), particularly in prominent shopping locations for Zucchini Stores, but isn’t interested in defending its territory from HUCCI (pronounced hoochie), which would like to open its own shop on that piece of land. The record of land ownership on a blockchain must be enforced by someone physical. Enter the PoliceDAO, or SecurityDAO, which function much like CleanWaterDAO. In practice, these DAOs will specialize in territories too, so they will look more like SouthwestCountyPoliceDAO.
DHLDAO really needs RoadBuidlersDAO to do a good job. So they start cooperating closely by buying up many RoadBuidlersDAO tokens a la Curve Wars. In fact, if it weren’t for DHLDAO, RoadBuidlersDAO wouldn’t have expanded to cover so much territory. Similar shenanigans exist with the shipping and air industry, which I won’t cover because I don’t understand as well.
So far this isn’t terribly convincing, so let’s go ahead and make some observations:
Physical infrastructure is still needed, and it’s hard to see a network state provide that, so they will not disrupt, but instead be orthogonal to traditional nations.
Sometimes one can just pack up and move; other times one must dig his heels in and fight. In these cases a nation is the better way to go because it has dispute resolution via the police/army.
This means interests and ideals will determine which network state one joins. Ethereum can already be said to be a network state – does the EF not own offices in Berlin?
Preliminary Conclusions
If your interests/ideals/way of life is mobile, you might consider joining a network state for whatever reason.
Cosmopolitans and people in between cultures might find the concept interesting. Otherwise, if you identify strongly with a certain culture or social group which lives in an area, you might find this irrelevant.
Nation states for the physical world, network states for the virtual world.
Network states want to ensure physical quality of life for their members, but they cannot do that themselves if they do not control large contiguous swaths of land. Hence the rise of a global-scope CleanWater/Air/Beaches/Electricity DAOs, now humanity as a whole will keep the Earth clean, instead of countries.
My EDC includes an iPhone 6S, Xiaomi Redmi Note 9 Pro, and when I really want to take pictures, a Sony RX100 IV.
In a fit to optimize everything in my life, I tried to optimize this away into one device, but couldn’t – because the thought process that had landed me in this situation was very sound and still applies even today. Let me explain.
What my Android phones were like
My first smartphone was an LG Optimus One, then a HTC One S. Both companies are terrible at software updates – the One S had its last Android update only 6 months after it was released – and I had bought it at full price, new! I was so pissed I vowed never to buy HTC again. When they went under, I was glad.
Ahem. Instead of ranting about it, let me just summarize my experiences with each phone.
LG Optimus One: eye opening introduction to smartphones; SLOW; obviously bad rear camera; SLOW. The lack of software updates was not an issue because the phone was so SLOW.
HTC One S: software updates discontinued after only 6 months, but I kept it going for 4 years with custom ROMs. All custom ROMs, by the way, will always have an issue or two, because these are things you can’t write software tests for – you have to actually test it in the real world. Problems I remember: Bluetooth headphones changing pitch very slightly because the wifi antenna is retuning itself for a better reception (they use the same antenna after all), wifi not reconnecting when coming back into range (custom ROM issue), random reboots (custom ROM issue), no TRIM support on stock ROMs so you have to install a custom ROM if you don’t want your phone to slow down after a few months. On the plus side, the camera was everything I wanted and it was a sexy phone.
LG G5: tended to produce larger (3-6MB) photos even though pictures were blurred by the noise reduction algorithm. Then it got stolen.
Now I’ll dedicate a whole section to why iPhones are so amazing.
iOS: perfection
It took me a lot of fiddling with my HTC One S to understand myself – namely that even though I like fiddling with my computer, I don’t want to fiddle with my phone.
With the iPhone 5S, 6 and 6S, I got the whole package – a great camera; never felt slow; I actually used it and didn’t think about maintaining it.
camera such wow
Often times, you’re with somebody, they make a face or are in an interesting situation, and you want to take a picture. In the Android world you have to choose your phone carefully because all these could be bad:
Unlock the phone/swipe to camera shortcut: the camera app could start very slowly (500ms okay, 1s or more bad)
Camera takes a long time (1s or more) to focus.
Long delay after pressing the shutter button and the camera actually taking a picture (500ms or more)
Picture quality great in daylight (aren’t they all), terrible in certain conditions (still true today).
Apple may not be the absolute best in one dimension (focus speed, detail preservation, megapixel count, sensor etc) but it always strikes the best balance, consistently, since 2013. Android flagships often have great hardware but the software lets it down.
For instance, this picture was taken on a Redmi Note 9 Pro in the last minutes of an evening. The noise reduction algorithm in low light situations is too heavy handed and smudges the whole picture, especially the grass. Despite this loss in detail, the picture is a hefty 5MB.
Redmi Note 9 Pro, low light
Here’s another bad photo in a low light situation from the iPhone 6S. Notice how the carpet texture is preserved well – the Redmi would have reduced the carpet into a blurry mess. This photo is only 2MB.
iPhone 6S, low light
other little details that just work
Did you know that digital compasses need to be calibrated? I don’t know how they do it, but on iPhones, it was always pointing in the right direction. The Redmi Note 9 led me down the wrong road several times, the compass being up to 90 degrees off. I calibrate it, and within a few minutes it’s wrong again. It’s such a small detail that ends up being a huge annoyance when traveling.
Redmi Note 9 Pro’s wifi/Bluetooth antenna is not the best. For instance, when paired with a cheap Bose QC25 bluetooth adapter, it can lose signal when I put my phone on the opposite side of my body!
iOS: after the honeymoon
After several years on iOS, I decided to experiment with Android again with a cheap phone, the Redmi Note 9 Pro, and I realized just what I had sacrificed.
It’s the attitude that’s the problem, when the company forces you to do things its way because you have no choice. In real life, we call them bullies.
Nobody else has your interests in mind either, except for the free open source software community. Even Microsoft places ads in Windows these days. Linux is the one place on the PC where I am not funneled towards someone’s agenda, thank god I learned to use it when I was a teenager.
Instagram does not have your best interests at heart. The official app is optimized to make you scroll forever and waste huge amounts of time. Thankfully, there is an alternative app on Android called Barinsta, which displays the same content in a normal way that doesn’t encourage you to waste an entire afternoon and doesn’t have ads. Such an app would never be allowed on the App Store, nor the Play Store.
Youtube does not have your best interests at heart. Just like Instagram, it encourages you to waste time with its Related Videos; autoplay is on by default; ads, popups that you can click on in the video area. I am not an idiot, I know that the difference between streaming a video and letting a video be downloaded so it can be played later offline is 0 – so why are they making me pay for this functionality with Youtube Premium? Thankfully there is Newpipe and Youtube Vanced (and its forks).
I could go on forever, but to make it short, imagine what the computing world would look like if software were written just for our (consumers) own benefit, and not just so companies could make money from us. That’s the free open source software movement, and F-Droid is full of apps which
don’t try to tack on a cloud/account/subscription model onto something which obviously doesn’t need one
isn’t some freemium hook and bait deal
can share files without relying only on cloud companies like Dropbox/OneDrive
Android as a smaller computer
I found myself using Android like a mini PC when I was too lazy to pull out my laptop.
Because it has a real filesystem, it’s easy to copy files (like movies or music) onto an Android phone and watch it on the plane. The iPhone would force me to use an app, which would force me to pay to download to watch/listen offline. Then I’d realize that I have no space left so I’ll have to give up on the idea.
iPhone vs Android – how to choose
Why would you buy an iPhone?
You go iPhone because you want things to just work – and you’ll make the necessary sacrifices to appease Apple so you can go about your daily life without having to think about your phone.
iPhone 12 Pro costs $406 to produce, and sells for $1000.
My iPhone 6S cost $200 in 2019, and I still got iOS 15 this year, so it’s definitely been worth it. At $1000, it’s probably still worth it, just because the software support is incredible – the 6S came out in 2015!
Still, I would never buy an iPhone new from Apple out of principle.
Why would you buy an Android?
You go Android because you want freedom and you don’t want to be shepherded into the behaviour patterns that big companies want you to do.
Expect little problems that would be a non-issue on iPhones, because nobody is as smart and detail oriented as Apple. Wait, what?
Think about it. Buying an Android flagship means you are paying $1000 for only 4 years of software updates (maximum, depends on vendor), and you’re losing the audio jack and microSD slot too! I might as well buy an iPhone already!
With dumbasses like these designing Android phones, and the fact that smartphone vendors don’t produce the processor nor Android, what do you expect?
Example: Xiaomi makes the Mi 12 Pro, which sells for $1100. I have the Redmi Note 9 Pro, which cost $180. The Gallery app has a problem: when I delete photos from the phone, the app still thinks the photos are there and there is no way to tell the app to refresh its database, short of reinstalling it!
In short, iPhones offer more than Androids at the $1000 price point. In the budget range, Androids are better value for money.
Removing the camera from the problem
I said before that no one is looking out for your interests. That includes smartphone review sites, who always make incredible claims about how much better photo quality is on this year’s crop of phones.
In daylight, quality is not a problem and hasn’t been since the iPhone 5S. The differentiator is low light performance. Smartphone cameras take multiple exposures in Night Mode to achieve better dynamic range. Noise reduction algorithm tuning is still an issue, because smaller sensors naturally do worse in the dark.
Huawei P40 Pro sample from DXOMark. Notice texture loss on jacket.Just to show how her jacket should look
Below is a photo from the RX100 in a similarly dark, if not darker, situation. Imagine if the same amount of noise reduction/blurring from the P40 Pro were applied to this photo – would you still be able to read the GANT label on his jacket? How would his scarf’s texture look like then?
Not great photos I know, just making a point here
Let’s just cut the bullshit out and say: no smartphone camera is going to beat a bigger sensor, especially if things are moving at night. The devil is in the details, and what I’m realizing more these days is that the details are often left out by people with a vested interest.
The solution is obviously to always bring a dedicated compact camera with you. Except that of course, I rarely do, because the RX100 IV is still bulky, and it takes time to turn on.
Also you must consider the question: why do you take photos? It’s satisfying to take a good picture, but showing it to others gives me more happiness, even if it isn’t perfectly composed. It’s complicated with an external camera. You can’t share instantly, you have to copy it over first. It’s a different pace, slower, more deliberate.
I call this one ‘Hippie Love Story’
Thanks to the way the world works, I’ll never get a mixture of an iPhone, Android, and a good camera.
It’s just easier to find a way to carry all 3 at once – I’ll figure it out one day…
Some time ago, in addition to being the trivia king of Fujitsu Primergy servers, I was also a master at finding used Macs for cheap on eBay. Nobody wants a Core 2 era Mac anymore, so naturally I bought a 2007 iMac 7,1 for 100EUR.
Now I have 8 Macs that I never use.
It was 100EUR because it would turn off randomly (power supply problem). Other than that it was perfect.
Life is so fast paced, nobody has time to repair broken things. I called a Mac repair store, even they didn’t have the time to repair it – too expensive to troubleshoot and take apart, they say, better to just buy another power supply. But they did leave me with a good tip – capacitors are the only thing that age and break down in a power supply.
It took me a year to finally get around to calling that repair store. I was constantly chasing the next nugget of knowledge, the next new hobby, the next acquisition. I have 14 jackets by the way, I just counted. I wanted to experience this, experience that.
When I bought that iMac, I was also chasing the next experience. But deep down, I was just chasing what I really enjoyed about computers when I was young – immersing myself in a project with no expectations whatsoever.
Pay attention to your self-talk (this goes for everything). “I’ve got to get it fixed by x date”, or “I’ve got to do this as quickly and efficiently as possible” sucks the fun out of it. Or “just gotta finish it quickly so I can move on to the next project” just misses the whole point of taking on such projects in the first place.
When I was ‘busy’ and ‘had to get all this done’, I didn’t get that much done and I was stressed and somewhat guilty at the end of the day.
When I told myself ‘you don’t have to do anything’, paradoxically I got so much done – because by not putting pressure on myself, I was able to reach flow.
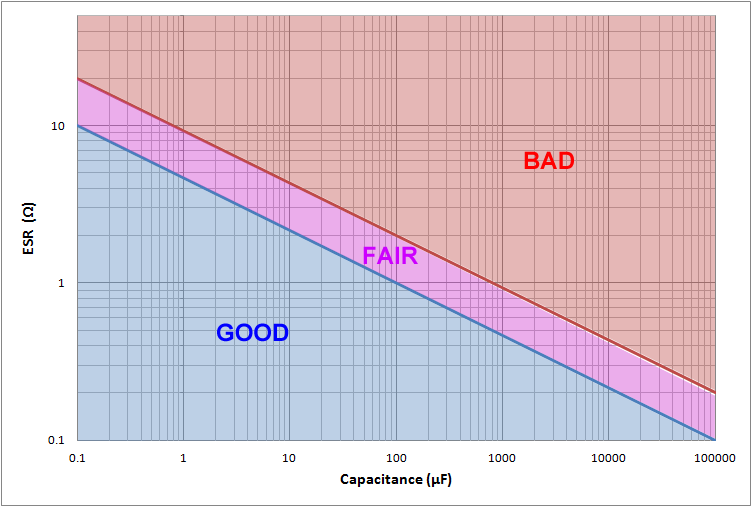
And so it happens that after putting this off for a year, I suddenly have the time and energy to use an ESR meter on every capacitor in the power supply. Here’s the data, just to show the condition of the capacitors after 15 years:
a 22uF capacitor can be considered ‘good’ until it hits an ESR of 1.8 Ohm
C406 and C407 were two small capacitors that lived under a large heatsink. C406 was totally gone, even though it wasn’t bulging. C407 had a in-circuit ESR of 0.97 Ohm. Compare this to C30?, which has the same capacitance, but is far away from the heatsink so it’s healthier at 0.19 Ohm. Although C407 is still “good”, it clearly has aged more.
C406: no capacitor should have an ESR that high
Buying the ESR meter, desoldering pump, desoldering the TO220 component and the heatsink to get to the capacitors, finding an electronic parts shop willing to sell me only 1 of each capacitor… imagine if I had approached all of this with the mindset of “I need to get this done”.
Since I wrote the last post my understanding has changed. My last post was close to, but not quite, hitting the mark.
The turning point was when I read Emily Ratajkowski’s “My Body”. In case you don’t know who she is, she’s a Victoria’s Secret model. I don’t consider her to be particularly mature yet, and there is a lot of anger in her book, which I correctly surmised came from her living in America (there, people are always outraged/offended about something). But after reading it, it became as clear as day:
Beauty is a front.
Imagine you’re a happy little girl. Life is good, you’re not thinking about sex or boys or anything.
the pressures of sexuality turn one from this…
Suddenly, at school, beauty starts to become important. In fact, people start to treat you worse and treat others better – and it seems that it’s all predicated on being hot.
(this happens for guys too, except that it’s about being cool. not that the girls notice that they’re doing the same thing – they can only see the guys who are cool)
Everybody is now rated on beauty, and it’s the one dimension you’re ushered into. You can’t escape. Even into your twenties and beyond until you’re a grandma, everyone keeps harping about how hot you are or how hot someone else is.
… into this.
Understandably some rebel, “why is it all about looks”, they say. Some opt out entirely, becoming the girl that no one notices, even if genetically they have what it takes to compete. Of course looks are important. But overemphasis on looks can create a subconscious rejection that, if one is not aware of their subconscious, can last a lifetime and stunt one’s potential.
This is for the girl who didn’t win the beauty contest. What if you won? You might end up angry and… I don’t know what’s the word for it but I’ll go with superficial for now… like Emily Ratajkowski.
Guys can’t escape the coolness ladder in high school/university – but in real life, it is skills, success, intelligence that you are judged on. Success can be interpreted in many different ways, and is entirely under your control (unlike beauty, which is up to your parents), so there is more freedom in that dimension.
Now you know a beautiful girl is just another girl, just with her own set of problems. But let’s not stop there.
Luxury brands aren’t actually rich and prestigious – once you subtract marketing costs, their profitability is only average, according to Jean Noel Kapferer’s New Strategic Brand Management.
A lot of work goes into making a front. On the small scale, you see girls trying to find the perfect angle in the selfie. On the larger scale, observe the efforts expended to convince you that a perfume you made is worth more than 20 Euros, because it’s prestigious/you’re going to be sexier/exclusive/you deserve to pamper yourself every once in a while with only the best. No, it’s worth 200! The price tags are the real achievement, not the product itself.
But we can take it a step further.
Your perception is a front.
I remember once when talking to a girl I liked, she said “but you don’t really know me, you just like your perception of me”.
I replied: “but that’s exactly why I’m here – I’m curious and want to know more about you.” Back then her objection felt silly and easily resolved with common sense – today it feels more understandable.
Anyway, women put up the front to attract – but they don’t want men who are bedazzled by the front! In a way, it is an intelligence/character filter.
(this is a human thing, not a man/woman thing – if you spent energy to put up a front to attract attention, you’d also hope that people would be interested in the person behind the front)
Master the front to not be blinded by it
Everything in my previous post simply comes naturally from this realization and applies to all other areas of life, which is why this is the true answer.
I spent YEARS overcoming this, but you know how it is when you learn something – it becomes part of you, and you start to think “of course it’s like this!” You forget all that hard work and mindset shifting you did.
Before this becomes common sense to me, I’d better write it down so that others won’t have to ruin their lives any further.
I was always afraid of talking to the girls whom I found really beautiful. Cute enough? yes, I could behave myself. But stunningly cute or hot?
we’re talking this level of hotness here
In middle/high school I wouldn’t even admit to myself that I wanted to look at them. In university, there was one girl I liked a lot, called Anne. I immediately started flirting with a girl sitting next to me that I wasn’t interested in the least. Everyone thought I liked her instead and started teasing me, that’s how good I was at fooling myself.
One day, after I was talking with another Chinese girl (I’m usually not interested in Chinese girls, especially this one), a friend asked me if I liked her. I said no, why? He said “because that’s how you talk when you’re flirting with someone”. And he was right. I knew that already, but somehow she was the only girl I could talk like that with (and somehow we both knew that I wasn’t really interested anyway).
How could I unfuck myself?!
In fact, first I would have to learn how to talk to strangers; how to talk to women I wasn’t attracted to; how to ask women out; how to ask women that I was attracted to out; and then I could start talking to women I was VERY attracted to. Oh, and asking them out too.
Dude, you say: what about “actually getting with the girl I was really attracted to”? Well, no. Firstly, whether such a girl is available or likes me is out of my control. Secondly, such girls are rare, and it’s rare enough that a normal girl likes me anyway! Thirdly: I really don’t need another reason to be needy.
It was easy to live with my defect in the clubs. The hot girls were so popular that you couldn’t get a word in anyway. I looked instead at the demure girl in the corner who actually would’ve been the belle du jour if she had taken the effort to dress up more. At the bus stop – I forced myself to talk to them, and resented them because they could just brush me away like a fly – apparently men all “have the freedom to go for what they want”, and what they want is sex, so they have to be on guard.
Well, not always. If someone just started talking to you somewhere, wouldn’t you be a bit wary until you knew what the deal was? I got into the habit of telling them that they were attractive right from the very beginning.
Always ask yourself: why? all the way down Let’s try one situation. Why am I not going to acknowledge/look at that girl who’s so cute? Because I’ve gotten rejected/ignored enough from girls like that in the past, now’s my time to reject/ignore them. Why? Because my ego wants to feel good. Why? OK, I admit it, my ego is stupid. I’ll just say hi, at least.
Let’s try another situation. Why am I not going to talk to that girl who’s so cute? Because I have absolutely no idea what to say! Why? Because “hi” can’t be good enough! Why? Because I’m sure so many other guys have approached her already! And you’re not better than them? Well… There are 4 possibilities, and here are 2 of them: a. You don’t feel like you’re good enough, and you’re actually not good enough. b. You don’t feel like you’re good enough, but you’re actually good enough (this is the hardest part. Soldier on, find success to build up your confidence)
When I started dancing, it was the same story all over again, even though now I actually had something to offer (a dance) instead of an awkward conversation leading nowhere. Still, I was afraid to ask the “good” girls out to dance, and anyway everybody wanted to dance with them so they were hard to get hold of. I also had my hands full figuring out what a “good dance” was.
Relationships (even short term ones) start because you have something of value to offer each other.
At the same time, you have no idea what people could want. She could want someone to call her a whore and slap her in the face. no really.
After some time I noticed that women have the same issue… they sometimes get afraid of dancing with this particular guy. They’re nervous they won’t be able to dance as well as they normally could. Or something.
Then one day, that started happening to me. The beginners would be hesitant and shy. Sometimes, when making a mistake with women whom I thought were better at dancing than me, they’d quickly apologize, make an excuse. Ah, they were a bit tired after work, were hungry, hadn’t danced for a while, whatever. They knew how to dance, so why were they making excuses for little mistakes that always happen anyway?
Sometimes, at dance parties where people know each other socially, women who knew me always wanted to dance with me so I could never get off the dance floor. Wait a minute, this situation sounds familiar – aren’t those hot women always hard to get ahold of because they’re always being asked to dance?
But nothing about me had actually changed! It was just their perception. I had just been improving myself linearly.
IT WAS JUST THEIR PERCEPTION.
I’m cool? I dance really well? …some people actually consider me cute? is it just because I’m 30-something these days?
Imagine, a girl probably goes through all this when she hits puberty. Just because she suddenly grew some breasts or maybe a butt, guys look at her differently and want to ask her out. It’s not like she became a better person. Maybe that’s why women aren’t completely bowled over by good looks like most men are. They know firsthand that it’s all a matter of perception.
Be conscious of why you think she’s perfect. See through that perfection to the imperfection. Every face has a “bad” angle.
guess who this is. Looks cute but eh, right?
Become the person you fear If you’re afraid of talking to fit, well dressed women who always seem like they’ve got better things to do than talk to you – be a fit, well dressed man who is so busy when he goes out of his way to talk to a woman, it’s because he thought “ugh, I really should focus on this other thing but hey she’s cute, let’s give this one a chance”.
“Well-dressed” from whose point of view? Yours. After all, her being well dressed is also your perception.
Once you become the person others fear talking to, you realize there’s nothing special about anyone.
Today I have more female friends than male friends from dancing. For the most part, they don’t understand this struggle, nor do they really care. Tell your girlfriend about how difficult it is to ask out women whose beauty scares you, and most likely they will make it about their egos “so you find other women more beautiful than me?”
For them, getting the attractive partner is not the problem. Keeping the attractive partner is the problem.
Get used talking to, and making friends with attractive girls, keeping in mind that one attractive girl is another man’s “10”
A male friend once told me that one of my female dance friends was so beautiful that he didn’t dare say much when she was around. I thought for a while. Yes, she was very feminine for a German woman, and was cute too. But I don’t think of her as a 10 (let’s think of scary girls as a 10), more like a solid 8. Remember, you’re already friends with 10s. They’re just not 10s to you. Neither are the 10s you’re afraid of really 10s.
Her name is Brooke Shields. Hopefully you’re not scared of her anymore.
If you still wanna read about this stuff instead of actually going out and taking action, here’s what the Good Looking Loser has to say on the topic.